
Apigee OPDK Meets GenAI: How We Solved the Streaming Crash
In the API First department of a major global bank, our mission is straightforward: we provide the "paved road" for the organization. We facilitate other banking teams—from trading to HR—with the tools and solutions they need for their API journeys, ensuring everything stays aligned with the bank’s strict conventions and procedures.
Usually, this means onboarding teams to our standard, robust Apigee OPDK platform. But when the bank entered the initial phases of adopting Large Language Models (LLMs) , "standard" stopped working.
The Initial Collision
The use case began with the release of a trial LLM service, utilizing a hybrid mix of models hosted both on-premise and on Azure. Adoption spiked almost immediately, and with it came a massive increase in SSE (Server-Sent Events) traffic —the streaming protocol used for those live, word-by-word chatbot responses.
We initially exposed these LLM APIs just like any other API: through our standard Apigee OPDK proxies. We quickly realized that the nature of Apigee OPDK simply wasn't optimized for this kind of traffic protocol.
The issues surfaced rapidly. Because OPDK Message Processors tried to buffer these long streams, we started noticing severe performance degradation—not just on the LLM services, but impacting the "Apigee Planet" as a whole. Connections were timing out because the Message Processors would kill the long-lived sessions required for deep LLM reasoning, dropping replies mid-conversation.
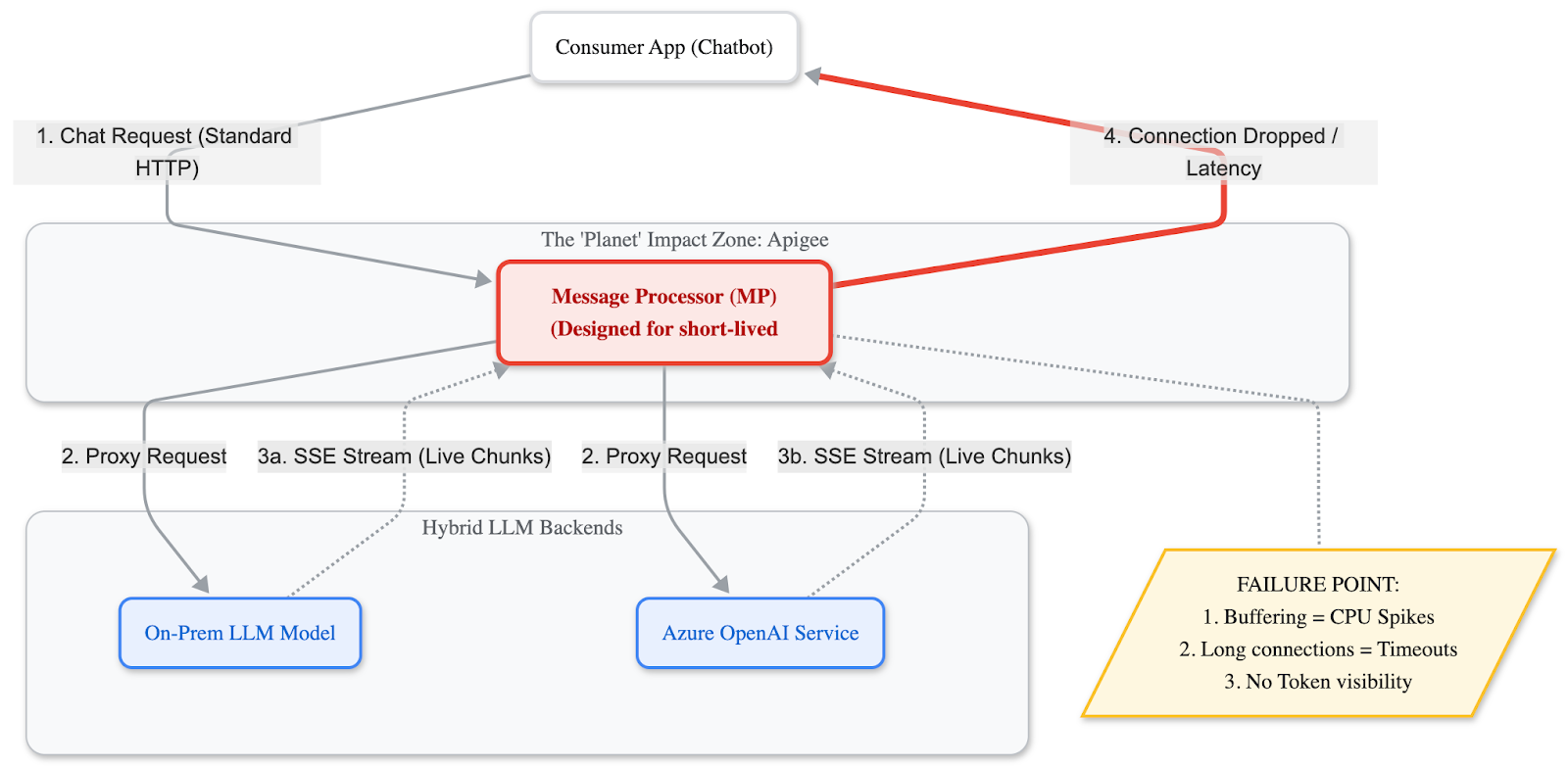
Figure 1: The Bottleneck. Standard Message Processors trying to buffer streaming LLM responses, leading to CPU spikes and connection drops.
The "Greedy" Requirements
To make matters more complicated, the consumer teams were—to put it lightly—greedy enough to ask for more. They didn't just want stability; they demanded:
- LLM Token-Based Quotas: Instead of standard traffic quotas, they wanted to be billed by the actual generated tokens.
- Fine-Grained Access Control (FGAC): They needed to control exactly which specific model a user group could access.
- Standard Governance: They still expected all the out-of-the-box benefits we provide like security, traffic management, and logging.
Phase 1: Fixing the Plumbing with Envoy
We had to pivot. Since Envoy Proxy was already part of the stack that the LLM service providers were using, the Apigee Envoy Adapter came on the table.
The initial tests were a breath of fresh air; the reliability and performance of the services stabilized instantly because Envoy handles SSE natively without buffering. We used the default Apigee Envoy Adapter to cover the basics: the authn filter handled JWT access token authentication, and ext-authz passed tokens to the Apigee Remote Service for standard authorization.
However, looking at the anatomy of the default adapter, we saw the problem. The standard filters operate heavily on the Request path, but the LLM tokens we needed to count live in the Response path. We had a gap.
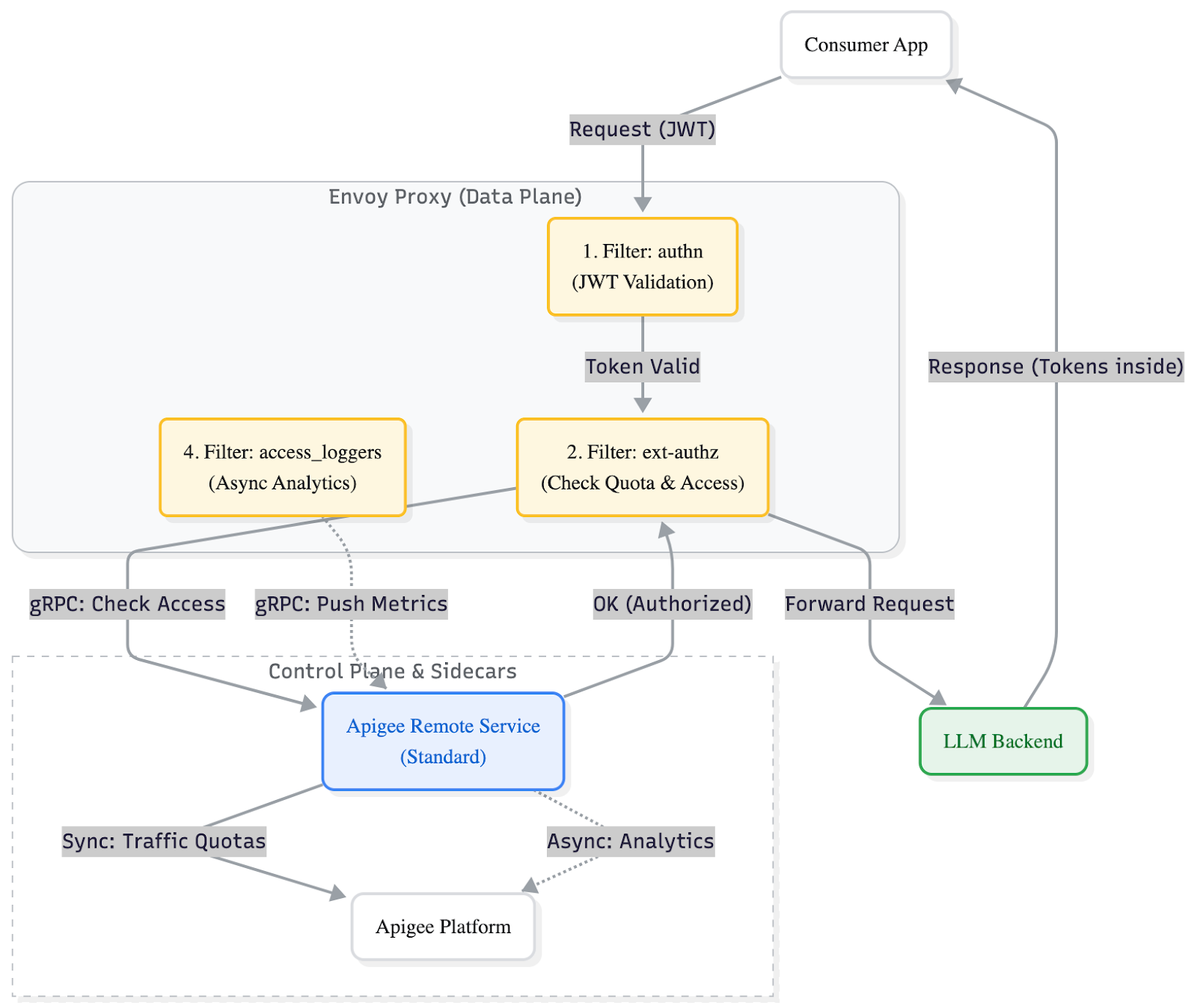
Figure 2: The Gap. The standard adapter handles security on the Request, but the Response (containing the tokens) flows back untouched, leaving us blind for billing.
Phase 2: The Engineering Hack
To solve this, we decided to extend the standard Apigee Remote Service. We reverse-engineered the Remote Service code (which is open source) and discovered we could utilize its existing Quota Manager—normally used for traffic hits—to manage LLM tokens as well.
We architected a custom solution using Envoy's ext-proc (External Processing) filter.
This filter taps into the response pipeline. It extracts the token usage data from the final stream chunk and makes a gRPC call to our customized Remote Service model. There, we apply the fine-grained access logic and deduct the exact token count from the quota bucket.
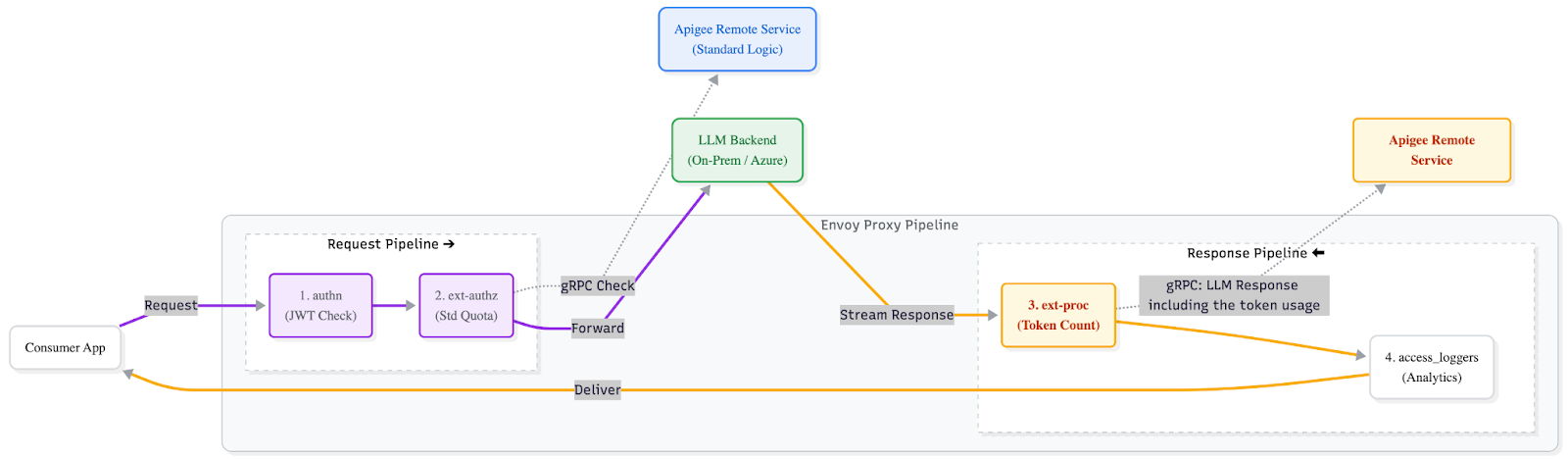
Figure 3: The Fix. Using ext-proc in the Response Pipeline to intercept the stream, count tokens, and sync with the custom Apigee Remote Service.
The Takeaway
It was a complex engineering challenge, but it allowed us to bridge the gap between legacy governance and modern AI innovation without compromising on either. We kept the API First team relevant, protected the platform from crashing, and enabled the bank’s AI journey to finally move at full speed.
However, the "how" of this solution lies in the details of the Envoy filter chains and the Remote Service customization. In a technical follow-up blog , I will dive deeper into the code and provide a hands-on demo showing how to configure the ext-proc filter and implement this pattern yourself. Stay tuned.
Call to Action
If you're looking to modernize your IT infrastructure and unlock the full potential of event-driven architecture, AppyThings can help. We've successfully implemented scalable, secure, and high-performance integration solutions for numerous clients. Reach out to us at AppyThings to learn more about how we can assist with your integration challenges and help your organization stay ahead in a digital-first world.
Contact Tom Hendrix at tom@appythings.com or call +32-474-365-980 for more information.